Coding as Intelligence: What Health Organizations Learn When AI Reads Every Chart
Coding as Intelligence: What Health Organizations Learn When AI Reads Every Chart


Something I hear frequently in conversations with healthcare organizations is that they're surprised by how much revenue and clinical detail documentation gaps are costing them. The patterns they suspected existed are usually bigger than they thought, and the dollar impact is bigger too. But they don't have a way to see how big the gaps truly are or what's causing them. Clinical documentation improvement, or CDI, is the function meant to catch these gaps.
I’m the director of product management at Arintra, where I lead strategy for our autonomous coding platform's expansion across specialties, analytics, and CDI. I’ve spent nearly a decade building AI products at the intersection of clinical documentation and revenue cycle, including product leadership roles at Truveta and Health Fidelity.
What’s become clear to me is that CDI has been so hard to scale because the underlying data layer hasn’t existed. That's what autonomous coding changes, and what I want to walk through.
What CDI Is and Why It Matters
CDI is the practice of making sure clinical notes capture the full picture of the care a provider delivered: the conditions, the complexity, the management decisions, and the care plan. It involves clinical accuracy and revenue, because the same notes that document patient care are also what coders, billers, and compliance teams work from.
Documentation improvement is especially important in family medicine, internal medicine, and primary care, because that's where most of the care coordination happens. When you're managing patients over time, you have both clinical and financial incentives to capture all the data and documentation you can.
Organizations are in very different places on this. Some have entire teams with dozens of people and leadership structures built around clinical documentation. Others are very new to the function and adopting it for the first time. The underlying constraints, though, are the same:
- Volume: The pace is too fast to pause for manual chart review. The train has to keep moving.
- Per-encounter value: Manual review of every chart is expensive, especially for low-dollar encounters.
- Lack of data: There's no visibility at scale into how hundreds of providers are documenting in granular detail.
According to a 2025 ACDIS survey, inpatient CDI productivity has been flat year over year, and only about 31 percent of respondents have any form of outpatient CDI program. Nearly half say they don't have one and don't plan to add one. So most organizations are stuck doing what they can, which usually means sampling.
What Sampling Can and Can’t Tell You
Sampling typically works like this: a CDI team or a few coders pull a small percentage of charts (usually 5 to 10 percent) each quarter and look for patterns. That’s enough to catch some high-level issues. It’s not enough to tell you about:
- Systemic patterns that aren't dramatic enough to show up in a small sample but add up across thousands of patient encounters
- Provider-level patterns, which you can't see in organization or specialty averages, even though that's where most behavior change happens
- The dollar value of any of it, because without comprehensive coding data tied to documentation, you can estimate impact but not measure it
So most organizations operate with educated guesses about where their documentation is weakest. That's not a knock on anyone. The work has always been done this way because an alternative didn't exist.
Why E&M Leveling Makes this Concrete
E&M leveling (deciding which evaluation and management code best matches a visit's complexity) is a good place to ground this, because it has a high financial impact, and is exactly the kind of thing sampling misses.
Providers aren't coders. They're focused on providing care, which is what they should be focused on. Converting clinical language to financial language is not what they were trained for. Leveling errors are almost always a byproduct of the fact that most providers don't have visibility into how their charting choices map to codes, and most organizations can't give them that visibility at scale.
Within a single specialty, with providers seeing similar patient populations, leveling can vary by 30 to 40 percent provider to provider. That's a wide enough spread that any organization-level average tells you almost nothing about what's happening on the ground.
Here are the patterns I see most often:
- G2211 under-capture. The Centers for Medicare & Medicaid Services (CMS) introduced this add-on code in 2021 to capture the complexity of longitudinal care, although it didn’t become separately payable until 2024. Most primary care visits qualify, but most providers don't document specifically enough to support it. At roughly $16 per encounter, that adds up to hundreds of thousands of dollars a year at a 50-provider practice.
- Missed modifier 25. When a provider sees a patient for a scheduled procedure and ends up evaluating a separate problem in the same visit, that's two billable services. Without the modifier, the payer only reimburses for the procedure. This is a common scenario, frequently missed.
- Downleveling on complex visits. Providers managing multiple chronic conditions often document carefully but bill conservatively, defaulting to a 99213 when the work supported a 99214.
Hierarchical Condition Category (HCC) capture involves similar dynamics for risk-adjusted populations. A primary care provider may have a thorough conversation with a patient about seven or eight active conditions, monitor them, evaluate them, and document them. But coding all of those at every visit isn't the provider’s main concern. The top three or four conditions get coded, but the rest may not.
None of these examples are exotic. The question is whether you can see them happening in time to do anything about it.
Autonomous Coding Creates the Data Layer
Here's how things work in most organizations today. You have clinical documentation sitting loosely in notes, and codes that eventually get billed. What sits in the middle is a black box. A provider or coder reads the note and applies a code. They didn't log that this code mapped to that piece of documentation. That's not a criticism, it's just how the work has always been done. But it means that organizations can’t capture the connection between documentation and coding as data.
Autonomous coding involves AI reading clinical documentation and assigning accurate, payer-aware codes without a human reviewing every chart. That’s the missing piece here. For every encounter, the system produces a structured record of the specific pieces of clinical evidence that align with the specific codes assigned.
At a single-chart level, that's useful for auditing. Scaled across hundreds of thousands of encounters, it becomes something more: an observation layer between the clinical language a provider uses and the financial language a payer needs.
That observation layer can be cut several ways:
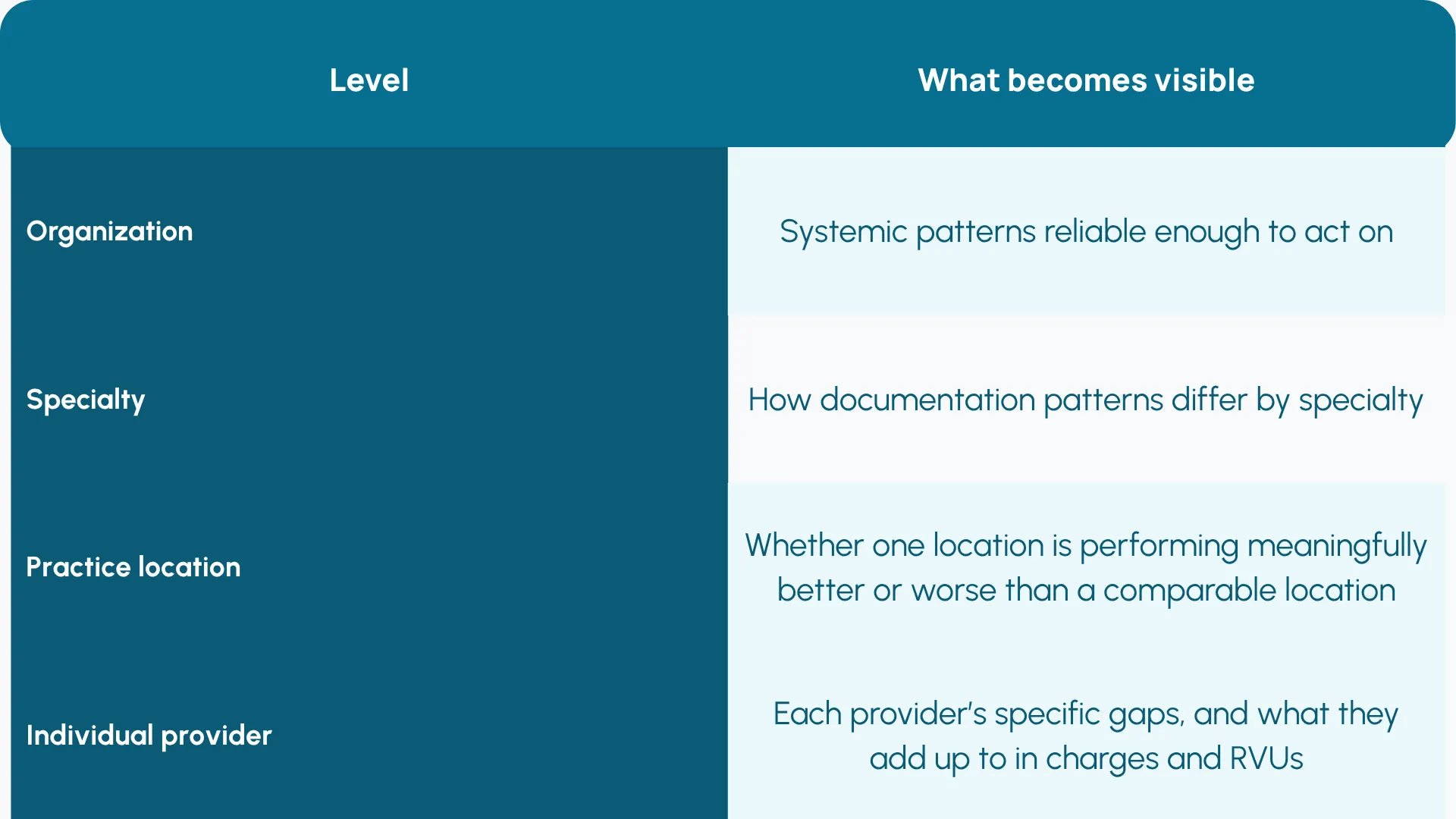
Each layer is useful, but providers change their behavior most when feedback is specific to them, because not every provider has the same issues. That's where you can have a specific conversation: you down-coded a 99214 to a 99213 thirty-four times this year, here's the documentation pattern behind it, here's what it cost in RVUs.
What Changes When Autonomous Coding Is Running at Scale
Once autonomous coding produces a comprehensive observation layer, CDI has the foundation it's been missing. The most useful version of CDI feedback is provider-specific and tied to dollars. There's an art to clinical documentation feedback. In my experience, it works when it's:
- Clinically meaningful, not just financially relevant. Providers are focused on patient care, as they should be. Converting clinical language to financial language is not the physician’s mission.
- Complementary, even additive, to clinical practice. Not an arbitrary documentation burden tacked on.
- Specific and quantified. Instead of "document more completely," you can show a provider their down-coded encounters, the pattern behind each one, and what supporting the higher-level code would have meant in charges and RVUs across the year.
I’ve also seen organizations take coding off providers' plates entirely once they trust the system. And because every code traces back to the documentation that supports it, the revenue uplift is compliant revenue with a built-in audit trail.
Coding, the Data Layer, and Ending Fragmentation
For a long time, revenue cycle processes and departments have been fragmented, siloed from each other, and operating with incomplete data. You’ve got CDI sitting in one department, coding in another, and denial management elsewhere.
What's different now is that autonomous coding produces the data layer that integrates them. The cleaner the clinical insight at the point of care, the more smoothly everything downstream runs.
Coding, CDI, denial prevention, authorization, population health: all of it draws from the same underlying record. Clinical documentation stops being a supporting function for what comes later and becomes the foundation on which everything else is built.

Explore More Resources

Is Your Health System Ready for Autonomous Medical Coding? Five Questions to Ask

"Arintra is Doing the Heavy Lifting" Mercyhealth Transforms a Coding Capacity Challenge into Revenue Integrity at Scale

Med First Finds Its ‘Easy Button’ With Arintra: Over 6% Revenue Uplift, Stronger Compliance, and Reduced Provider Burden in One Solution

Mercyhealth boosts revenue by 5% and cuts aging days by over 50% while supporting accelerated growth

The Hidden Power of Coding in Transforming Revenue Cycle Management

Arintra Receives A+* Partnership Rating in KLAS Emerging Company Spotlight Report

Arintra’s Fully Automated Medical Coding Solution Now Available in Epic Toolbox

Mercyhealth Transforms Revenue Cycle Management With Arintra's Autonomous Coding Solution

Still on the fence about autonomous medical coding? Here’s what you’re missing
